
简介
MySQL在5.5.3之后增加了utf8mb4的编码,mb4即4-Byte UTF-8 Unicode Encoding,专门用来兼容四字节的unicode。utf8mb4为utf8的超集并兼容utf8,比utf8能表示更多的字符
场景
当我们在表中插入emoji表情符号时,就会出现如下的问题,
SQLSTATE[HY000]: General error: 1366 Incorrect string value: '\xF0\x9F\x98\x83\xF0\x9F...'
for column 'name' at row 1
mysql的编码utf8最多支持3个字节, 其中已经包括我们日常能见过的绝大多数字体. 但3个字节远远不够容纳所有的文字, 日常用的emoji表情是4个字节,采用utf8mb4正好解决了这个问题
创建备份
在要升级的服务器上备份所有数据库,安全第一!
mysqldump -uroot -proot --all-databases > path/example.sql
检测MySQL Server版本
在MySQL 5.5.3版本中增加了对utfmb4的支持,所以需升级的版本即Mysql5.5.3+
修改配置文件
vim /etc/my.cnf
# 对本地的mysql客户端的配置
[client]
default-character-set = utf8mb4
# 对其他远程连接的mysql客户端的配置
[mysql]
default-character-set = utf8mb4
# 本地mysql服务的配置
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
修改之后重启mysql
检查MySQL是否启用了utf8mb4
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' \
OR Variable_name LIKE 'collation%';
+--------------------------+----------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/charsets/ |
| collation_connection | utf8mb4_unicode_ci |
| collation_database | utf8mb4_unicode_ci |
| collation_server | utf8mb4_unicode_ci |
+--------------------------+----------------------------------+
utf8mb4_general_ci/utf8mb4_unicode_ci区别
准确性:
1、utf8mb4_unicode_ci是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
2、utf8mb4_general_ci没有实现Unicode排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。
性能:
1、utf8mb4_general_ci在比较和排序的时候更快
2、utf8mb4_unicode_ci在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
总结:unicode_ci的精确度高于general_ci,unicode_ci的速度慢于general_ci
字符集
字符集参数
1、参数详解:
character_set_client: 客户端请求数据的字符集
character_set_connection: 服务器收到查询语句后转换成的字符集
character_set_database: 数据库使用的字符集
character_set_filesystem: 把os上文件名转化成此字符集,即把character_set_client
转换character_set_filesystem,默认binary是不做任何转换的
character_set_results: 查询结果的字符集,即返回给客户端的字符集
character_set_server: 服务器使用的字符集
character_set_system: 系统字符集,总是utf8,不需要设置,是为存储系统元数据(字段名等)的字符集
以 collation_ 开头的: 描述字符序
2、字符集转换流程:
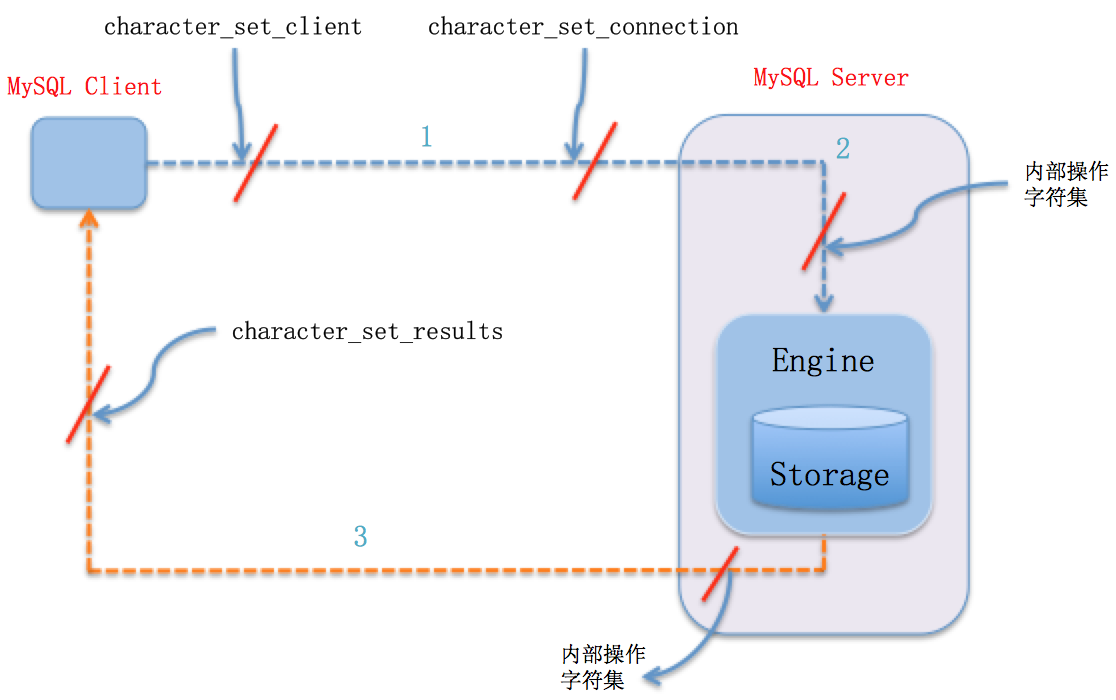
1) mysql Server收到请求时将请求数据从character_set_client转换为character_set_connection
2) 进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,步骤如下
A. 使用每个数据字段的CHARACTER SET设定值;
B. 若上述值不存在,则使用对应数据表的字符集设定值
C. 若上述值不存在,则使用对应数据库的字符集设定值;
D. 若上述值不存在,则使用character_set_server设定值。
3) 最后将操作结果从内部操作字符集转换为character_set_results
字符集修改
修改database默认的字符集
ALTER DATABASE database_name CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
修改table的字符集
ALTER TABLE table_name DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
修改column默认的字符集
ALTER TABLE table_name CHANGE column_name column_name VARCHAR(10) CHARACTER
SET utf8mb4 COLLATE utf8mb4_unicode_ci;
修复&优化所有数据表(数据库引擎MyISAM)
mysqlcheck -u root -p --auto-repair --optimize --all-databases
参考资料

